Core roadmap: towards v10
A long-term roadmap for the core design of Concourse, a general-purpose CI/CD tool.
Accompanying slides. Recommended viewing: episode 1 of Yu-Gi-Oh.
Concourse’s design philosophy is to be expressive, versatile, and safe while limited to a handful of simple, proven concepts. The design of these concepts should make good practices feel intuitive and bad practices feel uncomfortable.
Coming up with these designs can be very challenging. There are many different workflows and patterns across the software industry, and they each have to be deeply understood in order to know what the good and bad practices are.
This post provides a bit of insight into what we’ve been up to with Concourse’s core design - chiefly regarding ‘spaces’, which has become a bit of a white whale on our roadmap.
There are a lot of words here - sorry! If you just want to skim, I’ve added a single-paragraph summary under each roadmap entry.
Each roadmap entry corresponds to an RFC or an issue, linked in their header. If you want to get involved in our design process or just provide feedback, please check them out and submit a PR review! (Thanks!)
Table of contents
- Where is ‘spaces’?
- Where are we now?
- Where are we going?
- What comes after all this?
- Thanks!
Where is ‘spaces’?
For those of you not familiar with spaces, it was a big ol’ feature that enabled the following workflows:
- Dynamically running against things like branches/pull requests, which change over time (i.e. commits to a branch) and space (i.e. the set of branches themselves). Hence the name ‘spaces.’
- Fanning in using
passedconstraints across spaces. This is currently impossible to do with separate pipelines, because pipelines can’t reference each other’s resources. - Automatically cleaning up spaces for closed PRs, etc. This is annoying to automate and requires keeping track of state.
These workflows still make sense, so why is ‘spaces’ dead?
Well, I approached it the wrong way. To me, the idea of resources tracking change over time and space felt pretty solid from a theoretical standpoint. In hindsight, maybe it just sounded cool.
I had no reservations baking ‘spaces’ in to every layer of the stack - it would add more depth to all the existing ideas. Everything was going to change: the resource interface, the web UI, how jobs work… It was all so exciting!
But as time went on it became terrifying. It was a double-or-nothing bet. Either ‘spaces’ made sense everywhere, or ‘spaces’ didn’t make sense at all. I tried to carve out work that could be done before fully committing to spaces, but it didn’t make the monolithic feature any less monolithic.

Where are we now?
First off, I want to give a quick update on a couple of big things that you can expect in v6.0:
Issue #3602: a new algorithm
We are re-designing the algorithm used for determining the candidate input versions for a job. The new approach will rely less on brute force and will perform better with large installations.
This new algorithm fixes long-standing architectural issues with the old one, which loaded each pipeline’s entire build and resource version history into memory and determined valid candidates using brute force.
The key difference between the old and new algorithm is how passed constraints are implemented, specifically when multiple inputs depend on the same job:
plan:
- get: foo
passed: [foo-unit, integration]
- get: bar
passed: [bar-unit, integration]
- get: baz
passed: [integration]
In Concourse, this means “give me versions of foo, bar, and baz that have passed through integration together in the same build, with the same version of foo having passed foo-unit and the same version of bar having passed bar-unit.”
How does this work? Well, it’s hard to describe either algorithm succinctly, but I’ll try:
- The old algorithm goes through resource versions, newest first, and checks whether each version satisfies the input’s own
passedconstraints. Next it checks that any other already-chosen input versions which mention the same job in theirpassedconstraints also came from the same build, recursing and walking through versions until everything is satisfied. This process is brute-force, an uses a lot of CPU. - The new algorithm instead loops over build output version sets via the jobs listed in each
passedconstraint, assigning all the relevant versions for a given build at once as long as the versions match the other already-chosen versions assigned via builds of prior jobs in thepassedconstraint.
This new approach really simplifies things because the versions are inherently coming from the same build. Now that we don’t have to do the extra cross-referencing, the new flow can just make a handful of cheap database queries instead of having to load the whole pipeline’s dataset into memory.
We’ve been testing the old and new algorithm in two separate environments, each at the scale of 1,000 jobs with varying passed constraints and a sprinkle of version: every across four web nodes.
- The old algorithm starts off very fast but grows slower and slower as the pipeline dataset grows, eventually exhausting the
webnodes of RAM and swap. - The new algorithm starts off slightly slower than the old one - it’s hard to beat an in-memory dataset - but it stays stable, uses less CPU, and does not leak memory.
We’re making a few final touches as we to get as much performance out of the new algorithm as possible, since we don’t tend to touch it often. Once we’re finished, we’ll jump straight to…:
Issue #413: build re-triggering
The new algorithm changes the behavior for today’s pinning-based flow for re-triggering a build, so we’re going to implement proper support for build re-triggering and ship these two features together in v6.0.
Right now the only way to “re-trigger” a build is to pin each of the job’s upstream resources to the version from the build, trigger a new build, and go back and un-pin them all. It’s pretty cumbersome and error-prone.
It also kind of breaks with the new algorithm. Now that the new algorithm is based on build output sets and not version history, once the new build succeeds its older versions will end up being the first set attempted for that job, potentially propagating them to downstream jobs.
That’s not what I would expect from a re-trigger. I would expect a re-trigger to act “in-place,” while preserving the logs of the original failure for posterity.
To avoid this surprising change in behaviour, we’re going to implement build re-triggering properly and stop abusing the version pinning feature, which was originally designed for temporarily pinning a broken upstream dependency to a “known good” one.
Build re-triggering will be implemented in a way that preserves the order of the builds that the algorithm will go over. If the re-triggered build succeeds, its set of outputs will be available to downstream jobs based on the original build’s order.
Another benefit to implementing re-triggering soon is that folks using a pull request resource will have a much easier time re-triggering failed pull requests, without having to wait on the rest of the roadmap (i.e. ‘spaces’).
Where are we going?
So, going back to the ‘spaces’ initiative. The pieces really started to fall into place over the past few months, and I think I’ve arrived at a roadmap that accomplishes all of the goals of ‘spaces’ but in a significantly more Concourse-y way.
Instead of one monolithic feature, I have a bunch of smaller features to propose that are independently valuable and can be delivered in any order. As we complete them, a bigger picture will start to take shape.
Let’s jump right in!
RFC #24: resources v2
Resources v2 is the first major revision of the resource interface since Concourse’s inception. It’s a step to take very carefully. I think we’re finally ready to go.
UPDATE: Just kidding! This proposal has been superceded by something even more general: Prototypes! (RFC #37)
The v2 interface brings long-awaited polish to the interface: it renames in and out to get and put to match their step names, introduces a delete action, standardises TLS configuration, and revises terminology so as to not be coupled to the ‘versioned artifacts’ use case.
The latest proposal for Resources v2, RFC #24, is a lot like RFC #1 but with one big difference: ‘spaces’ is no longer a foundational piece of the interface. Instead, RFC #24 proposes that we generalize and simplify the interface to an extent that it can be used for various pipeline workflows, not just versioning artifacts.
The new direction is to leverage composition between resources and pipelines via config fragments, which can be passed from one resource to another or used for ((vars)) in a pipeline template. ‘Config fragments’ replace ‘versions’ in the interface, and are used as versions for the ‘versioned artifacts’ flow (today’s primary use of resources).
By generalizing the resource concept we set the stage for proper pipeline-level support for notifications (e.g. Slack alerts, GitHub commit status), trigger-only resources (e.g. time), and spatial resources (e.g. branches, pull requests) without tying each use case into the interface itself.
Now that ‘spaces’ is gone from the interface, the actual change in the interface protocol is somewhat cosmetic. As a result, Concourse pipelines will be able to use v1 and v2 resources side-by-side for all the same functionality. This way we can move forward with pipeline-level resource features without fragmenting the resource ecosystem!
RFC #26: artifact resources
Artifact resources are an interpretation of the generic resource interface that maps to today’s usage of the resource interface.
UPDATE: this is now RFC #38, “Resource Prototypes”
Artifact resources use config fragments as versions, modeling change to an external entity over time. This should sound familiar to anyone using Concourse today: they’re the sole use case that Concourse resources were originally designed around.
The ‘artifact resources’ proposal clarifies that this is now just one use case for the general resource interface, and outlines a few long-awaited features:
- Versions can be deleted using the
deleteaction in the resource interface. - The
putaction can emit multiple versions. Each will be recorded as an output of the build. - The automatic
getafter theputstep will be made opt-in. (Huzzah!)
The automatic get after each put is something that has confused and occasionally frustrated users, but we didn’t want to break backwards compatibility and we didn’t want users to have to ‘opt out’ (that’s too many knobs to turn).
This RFC will provide a backwards-compatible transition path to artifact resources. Check out RFC #26 for more details!
RFC #31: set_pipeline step
The first step on our journey towards ‘spaces’ is to introduce a simple, but critical piece of the puzzle: a set_pipeline step.
The set_pipeline step is used like so:
jobs:
- name: bootstrap
plan:
- get: ci
trigger: true
- set_pipeline: concourse
file: ci/pipelines/concourse.yml
This job will configure a concourse pipeline within the job’s team. The pipeline will be automatically unpaused, and no authentication is required.
The first thing this lets us do is deprecate the concourse-pipeline resource, which has two pretty fundamental problems:
- Having to configure auth is really awkward - you have to set up a local user and give the resource the keys to the kingdom.
- Keeping the version of
flywithin the resource in sync with your own Concourse’s version is a bit clunky.
With the set_pipeline step, both of these problems immediately go away and pipelines start to feel a more first-class rather than just being the tip of the abstraction iceberg.
RFC #32: projects
Ok, I promised to provide a tl;dr for each roadmap entry, but projects can’t really be summed up that easily. This is the most impactful feature on this roadmap.
- A “project” is a new concept bootstrapped by two existing ones: a resource from which to continuously load the project’s config, which specifies a build plan to execute whenever the project resource changes.
- Projects act as a namespace for pipelines, and provide a long-requested workflow for automating their configuration. As the roadmap goes on, this workflow becomes more and more powerful.
- Projects allow you to define project-wide resources which let you clean up duplicate definitions across your pipelines and support cross-pipeline
passedconstraints. - Projects also define project-wide tasks, which remove the need to thread a resource through all your jobs just to have the task configs to execute, and finally gives meaning to task names (the
xintask: x).
A project’s build plan can be used for anything you want. Small projects could use the build plan to run tests and/or perform various steps in a single build - a workflow more familiar to users of other CI systems:
name: ci
plan:
- get: booklit
trigger: true
- task: unit
Larger projects could use the build plan to execute set_pipeline steps. Concourse has long encouraged users to keep their pipelines under source control, but it never enforced it: fly set-pipeline was still a manual operation, and users would often forget to check in their changes. Projects will fix that:
name: ci
plan:
- set_pipeline: booklit
Small projects may start without pipelines and start using pipelines as they grow. Our original slogan, ‘CI that scales with your project,’ is now pretty literal! The hope is that by introducing build plans without requiring knowledge of pipelines and jobs, we’ll have made Concourse’s learning curve more gradual and made Concourse feel less overkill for side-projects.
This feature will have far-reaching implications for Concourse, so it won’t be sneaking in quietly. I’ve opened RFC #32 and would really appreciate feedback!
RFC #33: archiving pipelines
Archiving pipelines is a way to soft-delete a pipeline while still being able to peruse the build history for a pipeline you no longer want.
Well, after that bombshell this one’s pretty easy to explain. Let’s take a look at our own Concourse team’s pipelines:

Look at all that cruft! So many old, paused or bit-rotting pipelines which I really don’t care about anymore but don’t really have the heart to delete. That old-concourse pipeline served us well for years - it has sentimental value. In some cases you may also want to keep the history around for auditing purposes.
Archiving pipelines will allow you to humanely retire a pipeline in a way that gets it out of your way while still allowing you to peruse the build history should you ever need to. Archived pipelines are no longer active and will allow you to re-use their name without bringing the old pipeline back.
There’s already an open pull request for this: #2518 - shout-out to @tkellen! The ball has been in our court for a while to figure out the UI/UX, so we’re just going to submit a new RFC and work out all the details.
RFC #34: instanced pipelines
Instanced pipelines group together pipelines which share a common template configured with different ((vars)). They provide a simple two-level hierarchy and automatic archiving of instances which are no longer needed.
Instanced pipelines are an important piece of the ‘spaces’ puzzle: it’s how users will navigate through their spatial pipelines, and it’s what keeps no-longer-relevant spaces for e.g. merged PRs and deleted branches from piling up forever.
Pipeline instances are created using the set_pipeline step like so:
plan:
- set_pipeline: branch
instance_vars:
branch: feature/projects
- set_pipeline: branch
instance_vars:
branch: feature/new-algorithm
At the end of a build which uses set_pipeline, all instances of the named pipelines which were not configured by the build will be automatically archived.
Check out RFC #34 for more details!
RFC #29: spatial resources
Spatial resources are resources whose check monitors spatial change, not change over time. Two common examples are the set of branches or open pull requests for a repo. The across step allows a build to process each ‘space’ and trigger on changes to the set.
UPDATE: the syntax for this step has since been tweaked so that multi-var matrices don’t require nesting across steps.
When used with the new across step, the set_pipeline step, and instanced pipelines, this enables dynamic pipeline configuration across spatial change.
The final piece of the puzzle for ‘spaces’ is the addition of an across step. This step points to a resource and has a plan which will execute for every config fragment returned by the resource’s check, all within one build.
Let’s first look at a simple use case, which is to execute a task across many variants:
plan:
# ...
- across: supported-go-versions
as: go
do:
- task: unit
image: go
In this case, imagine we have a supported-go-versions resource whose check returns a config fragment for each tag and digest based on a pre-configured list of supported tags (e.g. 1.10, 1.11, 1.12), and whose in/get fetches the image.
When nested, the across step enables dynamic build matrices:
plan:
# ...
- across: supported-go-versions
as: go
do: # needed so we can define another 'across'
- across: other-things
as: some-input
task: unit
image: go
When used with set_pipeline and instanced pipelines, it enables dynamic pipeline matrices:
plan:
- across: repo-branches
as: repo-branch
set_pipeline: branch
instance_vars:
branch_name: ((repo-branch.name))
(Assuming we provide the ability to access fields of an artifact with ((vars)).)
RFC #27: trigger resources
Trigger resources allow jobs to specify parameters that can trigger new builds but don’t have anything to fetch - they just propagate config fragments to the build.
UPDATE: this has turned into a get_var step, rather than a param step
This is also a relatively simple feature, but it will improve today’s usage of the time resource by having per-job trigger semantics rather than having all jobs downstream of one time resource leading to a thundering herd of builds hitting your workers all at once.
Rough sketch:
jobs:
- name: smoke-test
plan:
- param: 10m
trigger: true
Semantically, param is similar to get but with one key difference: there is no central version history. Rather than being used as an artifact, the resource is used solely for its config fragments. Concourse will check against the job’s last used config fragment for the trigger resource, 10m, and if a different fragment is returned the job will trigger with the new one.
This skips the get, eliminates the thundering herd issue (because all jobs have their own interval), and could enable an interesting pattern for manually-parameterized builds: just write a resource type that can fetch user-provided config fragments from some external source (i.e. a repo).
Here’s one idea of what that may look like, where the config fragments returned by param are somehow usable with ((vars)) syntax in subsequent steps:
plan:
- param: environment
- task: smoke-test
vars:
environment: ((environment.name))
Another interesting use case would be to use it as a instance_fragment with the set_pipeline step.
This idea is pretty half-baked - I’ve been mainly focusing on the ‘spatial resources’ idea. Follow along in the RFC #27 and help the idea develop!
RFC #28: notification resources
Notification resources will allow you to monitor the flow of a resource through your pipeline and emit build status notifications (e.g. Slack alerts, GitHub commit status) without having to sprinkle put steps all over your pipeline.
Have you ever wanted to reflect your CI build status on your GitHub commits? Or send a Slack notification whenever the build is fixed or broken?
If so, you’re probably aware of how ugly it can make your pipelines, both in YAML and in the UI.
A simple pipeline quickly turns into a mess of boxes and lines:
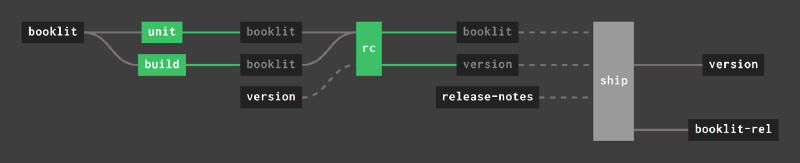
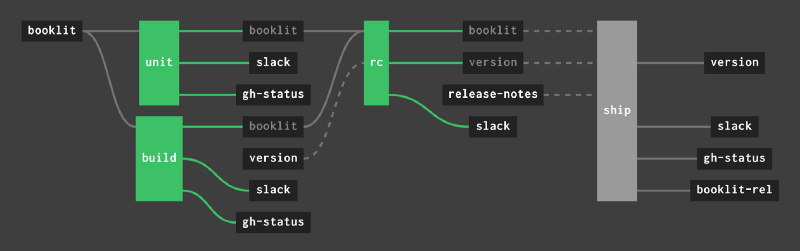
Not only is it a lot of manual work to copy-paste those on_success and on_failure hooks, when you finally configure it it really ruins the signal-to-noise ratio of the pipeline UI.
So, the plan for notification resources is to leverage composition, a pattern set forth in the Resources v2 RFC (#24). Instead of annotating every single job, you annotate a resource, and any time that resource is used in a build a notification will be fired, by executing the notification resource’s put step with the config fragment of the original resource (e.g. ref: abcdef) and the status of the build.
This way you don’t have to update all of your jobs, and notifications don’t clutter up the pipeline UI. Neato!
This idea is also a bit half-baked - follow along in RFC #28 when you have time!
What comes after all this?
I dunno.
I have a lot of respect for software that is eventually considered ‘done.’ I would really like Concourse’s core design to achieve that someday.
We’ll always have things to improve, whether it’s through better efficiency, better UX, support for new underlying technologies (Kubernetes, Nomad), or just making our codebase more accessible for contributors. But from a core design standpoint, I think the most important thing is stability.
The software industry changes quickly. Hot new tools show up all the time and get replaced by newer and better tools. I don’t want our users to have to keep re-doing their CI stack just to keep up.
Concourse should insulate projects from the constant churn in the industry by providing a solid set of principles and abstractions that hold true regardless of the underlying technology.
We will continue to listen to user feedback and improve Concourse. Our goal is for it to support good patterns and prevent anti-patterns that we can identify in workflows across the industry. Thankfully patterns don’t change as frequently as tools do.
Thanks!
Everything I’ve outlined here comes from years of feedback through all of your GitHub issues, forum posts, and conversations in Discord (or Slack for you OGs). I’m very thankful for those of you that have stuck around and helped us understand your workflows, and I’m especially grateful for your patience.
For those of you who couldn’t wait and ultimately had to switch tools, I hope we accomplished one of our original goals, and I hope to see you back in the future!