Suspicious Volume Usage on Workers
As a Product Manger at Pivotal I’m often called on to help with our customer’s Concourse-related issues. I recently spent some time hunting down an issue around suspiciously high volume usage on Concourse workers. It was an interesting problem that I wanted to share with the broader Concourse community.
Platform Management Pipelines
One of the primary use case for Concourse within the Pivotal Cloud Foundry (PCF) ecosystem is to automate the toil of manual maintenance against the platform; specifically PAS and PKS. For the purposes of this issue, the specific details of the pipeline doesn’t matter but an understanding the general flow of the pipeline will help frame problem:

In these pipelines the pivnet-resource is responsible for monitoring new product versions on network.pivotal.io (aka PivNet). When a new product version is released on PivNet, the pivnet-resource picks it up and initiates a download. These files are relatively large, from 500mb to over 1 GB
Recreate _ all _ the workers?
Over the course of the past year or so we would get sporadic reports of customers who used Concourse for PCF management running out of space on their workers. The typical manifestation of it comes from a failed to stream in volume error. It would appear that workers were running out of space; but it wasn’t clear why. To mitigate the issue Concourse operators would be forced to periodically re-create their workers to get a “clean slate”.
But why?
Having to periodically recreate workers is a huge pain and it doesn’t give operators a lot of confidence in Concourse itself. The team decided to take a look into the root cause of this issue. We wanted to understand whether this was a bug in the system and whether we could do something to address it.
After some poking and prodding, I think we figured out what was happening in this specific scenario. Using the same simplified pipeline above, consider the following scenario:
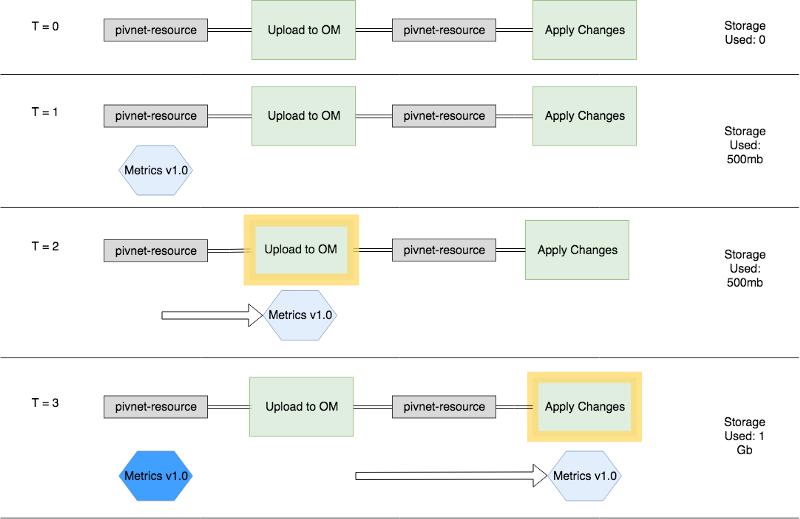
- At t=0 the pipeline is configured and idling; monitoring the external system for a new version.
- At t=1 a new version of the “Metrics” product is released on PivNet, picked up by Concourse, downloaded and begins to flow through your pipeline
- At t=2 the Upload to OM (OM == Ops Manager) job kicks off and does its thing
- At t=3 the artifact is used for some long running process like Apply Changes on OM. Concourse will hold on to that downloaded data since its still running
But wait, what’s that new Metrics1.0 box in deep blue at t=3? Well, its not uncommon for the metadata of a release to be modified just-after release. This could be a tweak to metadata (e.g. support dates, dependencies, supported stemcells, etc.), which causes PivNet to report a new version. Semantically, its still reported as Metrics v1.0 but Concourse will pick it up nonetheless. Because of this change we have effectively doubled the amount of storage used!
I think we learned a valuable lesson today…
The problem I described was a specific to the usage of the pivnet-resource, but there are a lot of common takeaways:
- Spend some time to understand your resources! The specific implementation of check can drastically affect your pipeline
- Be wary of using large files with long running jobs. I could see how someone could easily re-create a similar scenario with other resources
- Consider separating out the act of downloading an artifact from the act of operating on the artifact. For example, I found that other teams in Pivotal worked around this by landing their PivNet artifacts in an s3 bucket and picking it up in the next job via the s3-resource
- Set up some monitoring! You can catch errors and creeping disk use this in metrics dashboards
No seriously, why does this happen?!
In this blog post I covered a lot of the symptoms of the problem and touched on some abstract reasoning on why this happens. In the next blog post we (and by “we” I mostly mean Topher Bullock) will cover the specific technical details of Resource Caching on Concourse so you can have a better understanding of exactly why this happens.