Introduction to Task Inputs and Outputs
Understanding how task inputs and outputs work in Concourse can be a little confusing initially. This post will walk you through a few example pipelines to show you how inputs and outputs work within a single Concourse job. By the end you should understand how inputs and outputs work within the context of a single job.
Let’s define some jargon first.
- step : A step is a container running code within the context of a Concourse job. A step may have inputs and/or outputs, or neither.
- Job plan : A list of steps that a job will execute when triggered.
- Inputs and Outputs : These are directories. Within Concourse they’re generically referred to as artifacts. These artifacts are mounted in a step’s container under a directory with some-name. You, as a writer of Concourse pipelines, have control over what the name of your artifacts will be. If you’re coming from the Docker world, artifact is synonymous with volumes.
To run the pipelines in the following examples yourself you can get your own Concourse running locally by following the Quick Start guide. Then use fly set-pipeline to see the pipelines in action.
Concourse pipelines contain a lot of information. Within each pipeline YAML there are comments to help bring specific lines to your attention.
Example One - Two Tasks
This pipeline will show us how to create outputs and pass outputs as inputs to the next step(s) in a job plan.
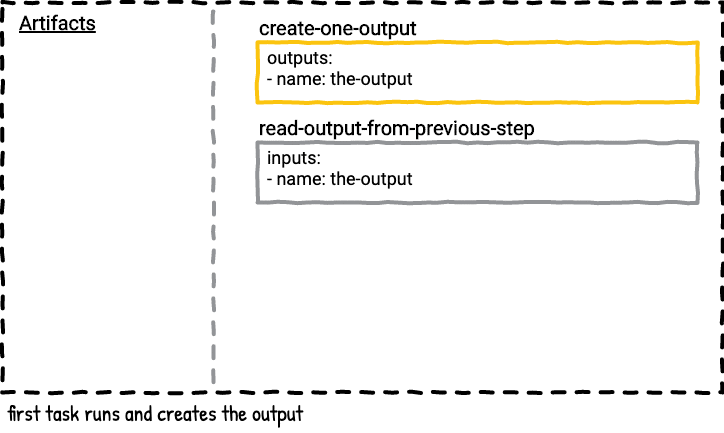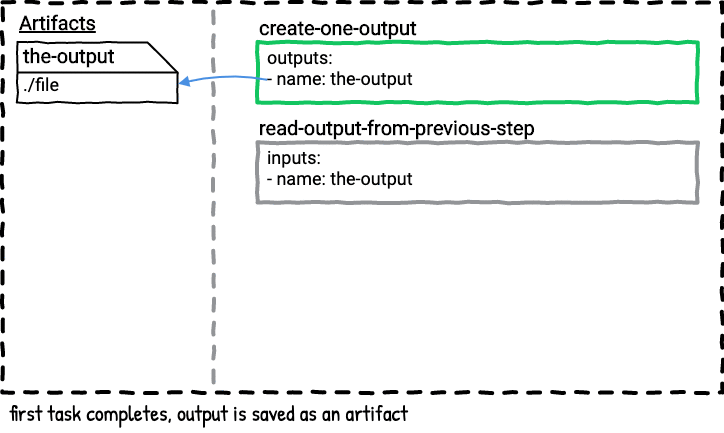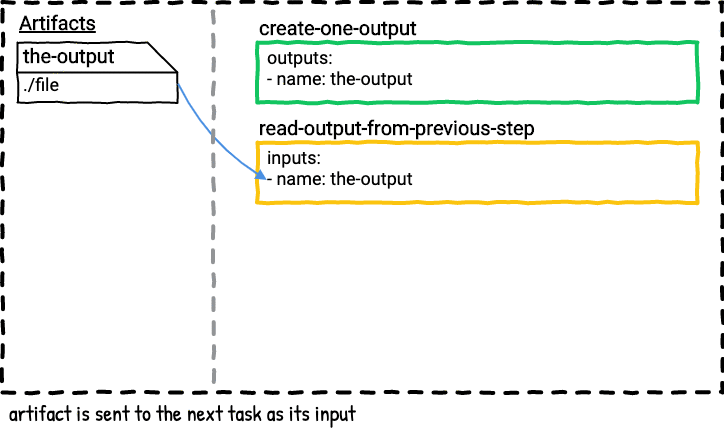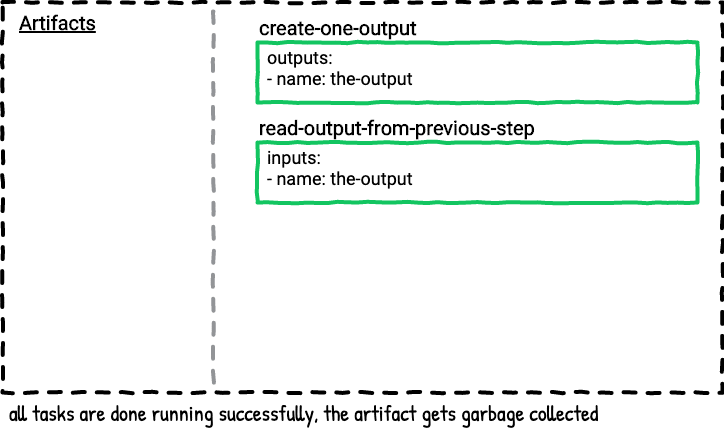
This pipeline has two tasks. The first task outputs a file with the date. The second task reads and prints the contents of the file from the first task.
---
jobs:
- name: a-job
plan:
- task: create-one-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: alpine}
outputs:
# Concourse will make an empty dir with this name
# and save the contents for later steps
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file
- task: read-ouput-from-previous-step
config:
platform: linux
image_resource:
type: registry-image
source: {repository: alpine}
# You must explicitly name the inputs you expect
# this task to have.
# If you don't then outputs from previous steps
# will not appear in the step's container.
# The name must match the output from the previous step.
# Try removing or renaming the input to see what happens!
inputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
cat ./the-output/file
Here’s a visual graphic of what happens when the above job is executed.
Example Two - Two tasks with the same output, who wins?
This example is to satisfy the curiosity cat inside all of us! Never do this in real life because you’re definitely going to hurt yourself!
There are two jobs in this pipeline. The first job has two steps; both steps will produce an artifact named the-output in parallel. If you run the writing-to-the-same-output-in-parallel job multiple times you’ll see the file in the-output folder changes depending on which of the parallel tasks finished last. Here’s a visualization of the first job.
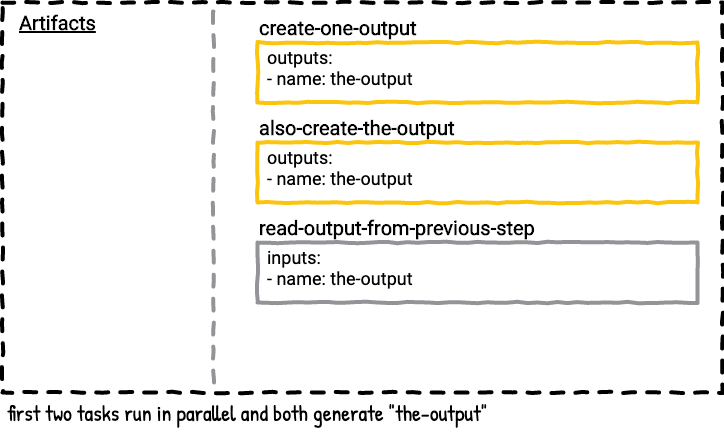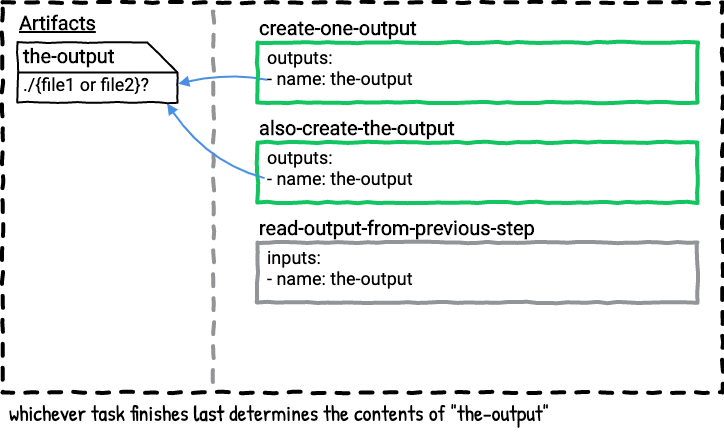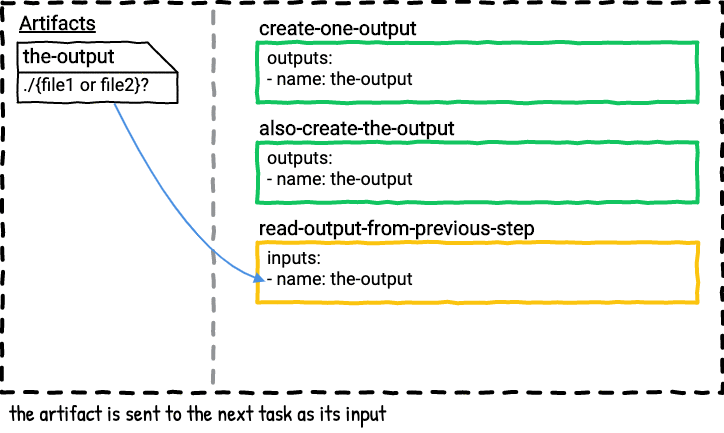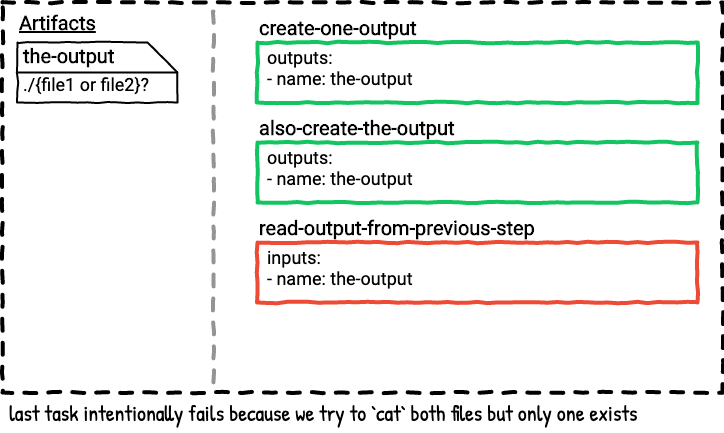
The second job is a serial version of the first job. In this job the second task always wins because it’s the last task that outputs the-output, so only file2 will be in the-output directory in the last step in the job plan.
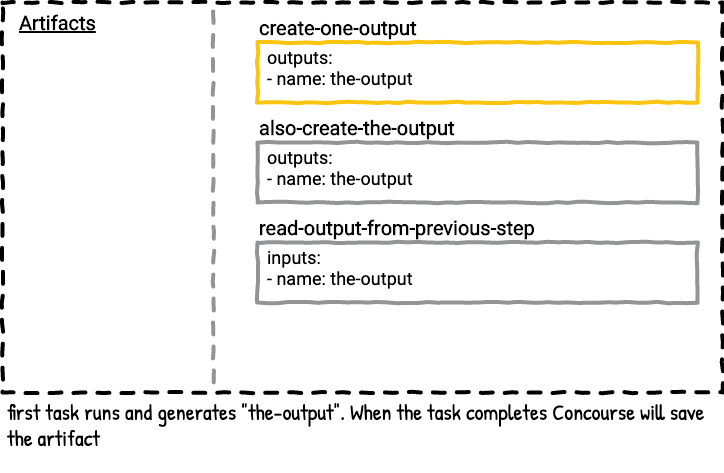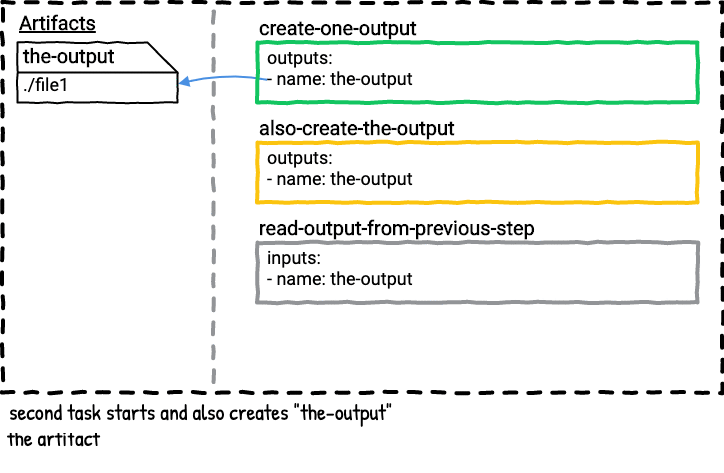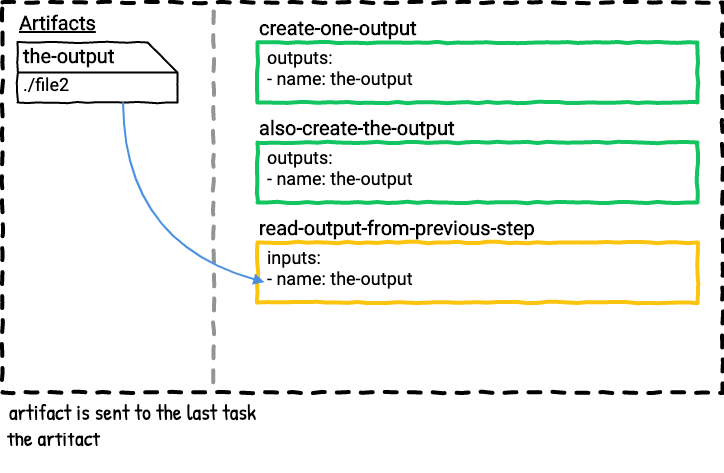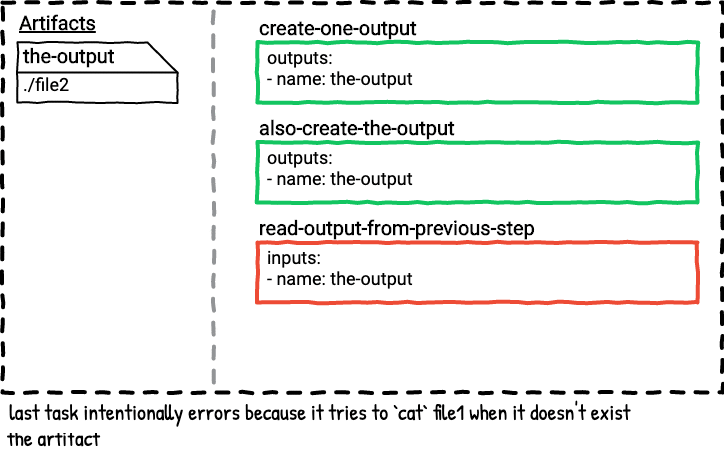
This pipeline illustrates that you could accidentally overwrite the output from a previous step if you’re not careful with the names of your outputs.
---
jobs:
- name: writing-to-the-same-output-in-parallel
plan:
# running two tasks that output in parallel?!?
# who will win??
- in_parallel:
- task: create-the-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file1
- task: also-create-the-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file2
# run this job multiple times to see which
# previous task wins each time
- task: read-ouput-from-previous-step
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
inputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah ./the-output
echo "Get ready to error!"
cat ./the-output/file1 ./the-output/file2
- name: writing-to-the-same-output-serially
plan:
- task: create-one-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file1
- task: create-another-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file2
- task: read-ouput-from-previous-step
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
inputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah ./the-output
echo "Get ready to error!"
cat ./the-output/file1 ./the-output/file2
Example Three - Input/Output Name Mapping
Sometimes the names of inputs and outputs don’t match, or they do match and you don’t want them overwriting each other, like in the previous example. That’s when input_mapping and output_mapping become helpful. Both of these features map the inputs/outputs in the task’s config to some artifact name in the job plan.
This pipeline has one job with four tasks.
The first task outputs a file with the date to the the-output directory. the-output is mapped to the new name demo-disk. The artifact demo-disk is now available in the rest of the job plan for future steps to take as inputs. The remaining steps do this in various ways.
The second task reads and prints the contents of the file under the new name demo-disk.
The third task reads and prints the contents of the file under another name, generic-input. The demo-disk artifact in the job plan is mapped to generic-input.
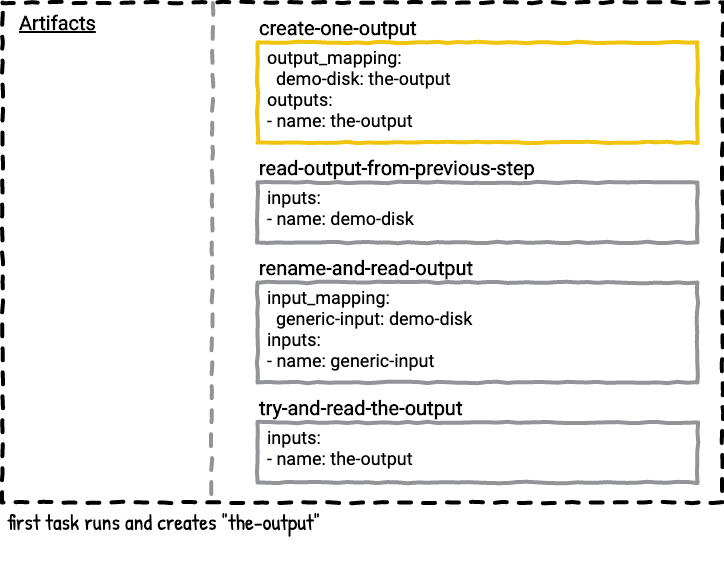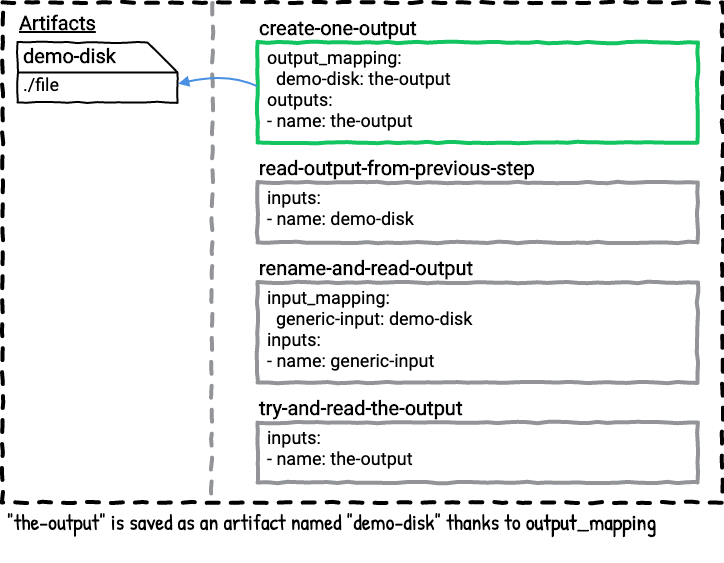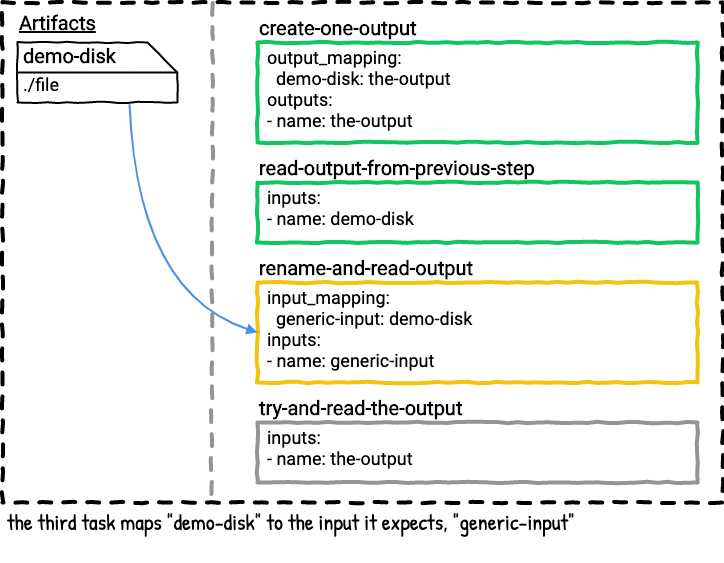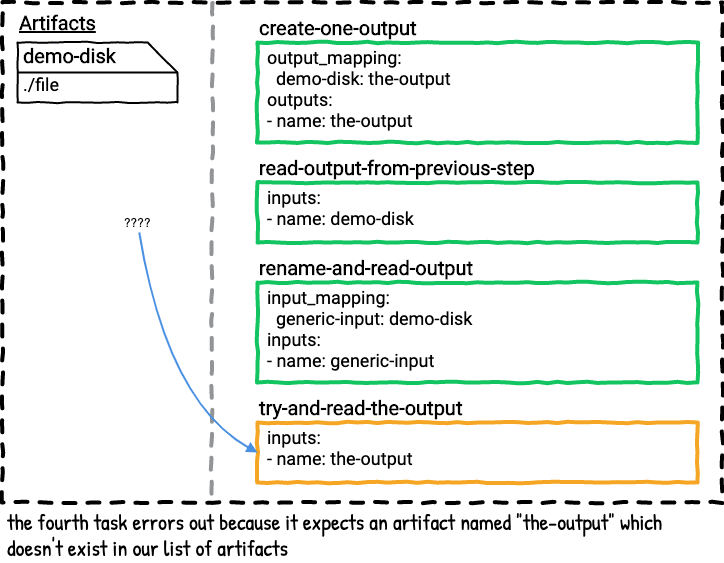
The fourth task tries to use the artifact named the-output as its input. This task fails to even start because there was no artifact with the name the-output available in the job plan; it was remapped to demo-disk.
Here’s a visualization of the job.
Here’s the pipeline YAML for you to run on your local Concourse.
---
jobs:
- name: a-job
plan:
- task: create-one-output
# The task config has the artifact `the-output`
# output_mapping will rename `the-output` to `demo-disk`
# in the rest of the job's plan
output_mapping:
the-output: demo-disk
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file
# this task expects the artifact `demo-disk` so no mapping is needed
- task: read-ouput-from-previous-step
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
inputs:
- name: demo-disk
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
cat ./demo-disk/file
- task: rename-and-read-output
# This task expects the artifact `generic-input`.
# input_mapping will map the tasks `generic-input` to
# the job plans `demo-disk` artifact
input_mapping:
generic-input: demo-disk
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
inputs:
- name: generic-input
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
cat ./generic-input/file
- task: try-and-read-the-output
input_mapping:
generic-input: demo-disk
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
# `the-output` is not available in the job plan
# so this task will error while initializing
# since there's no artiact named `the-output` in
# the job's plan
inputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
cat ./generic-input/file
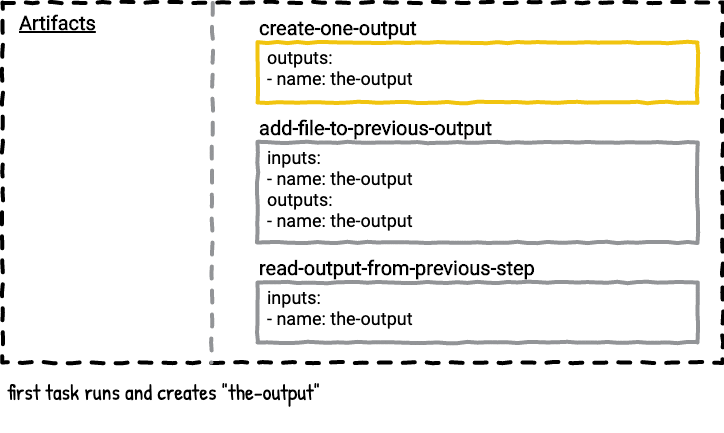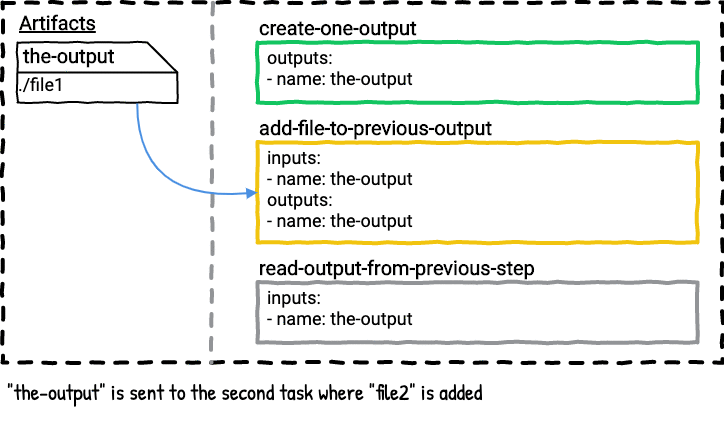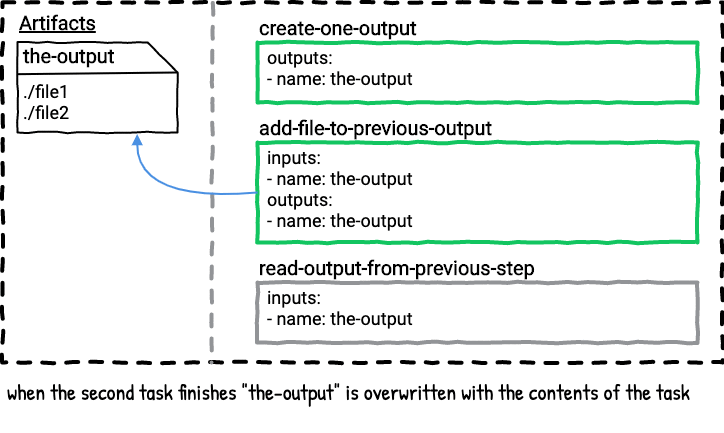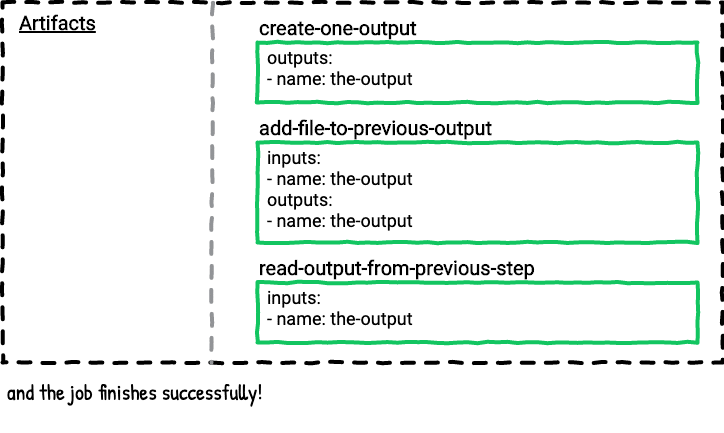
Example Four - Can you add files to an existing output artifact?
This pipeline will also have two jobs in order to illustrate this point. What happens if we add a file to an output? If you think back to example two you may already know the answer.
The first task will create the-output with file1. The second task will add file2 to the the-output. The last task will read the contents of file1 and file2.
As long as you re-declare the input as an output in the second task you can modify any of your outputs.
This means you can pass something between a bunch of tasks and have each task add or modify something in the artifact.
---
jobs:
- name: add-file-to-output
plan:
- task: create-one-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file1
- task: add-file-to-previous-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
# this task lists the same artifact as
# its input and output
inputs:
- name: the-output
outputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output/file2
- task: read-ouput-from-previous-step
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
inputs:
- name: the-output
run:
path: /bin/sh
args:
- -cx
- |
ls -lah ./the-output
cat ./the-output/file1 ./the-output/file2
Here’s a visualization of the job.
Example Five - Multiple Outputs
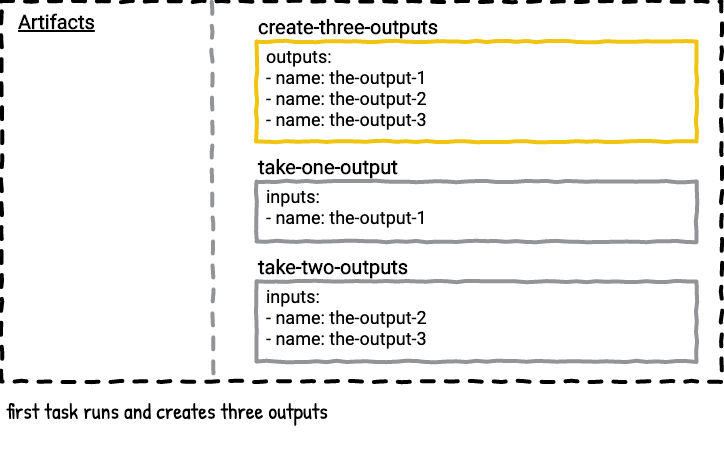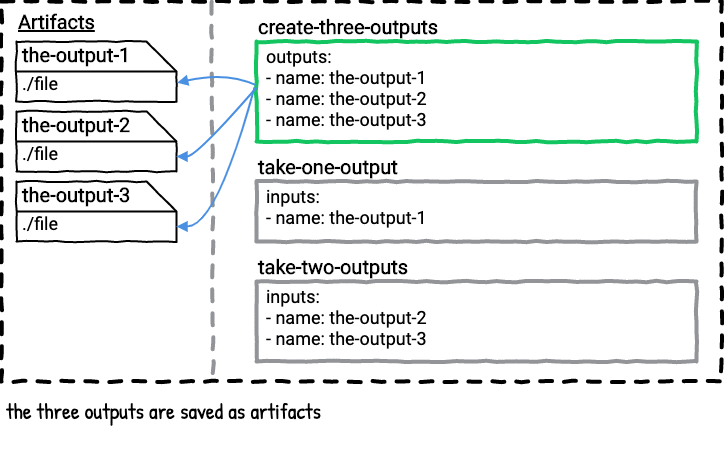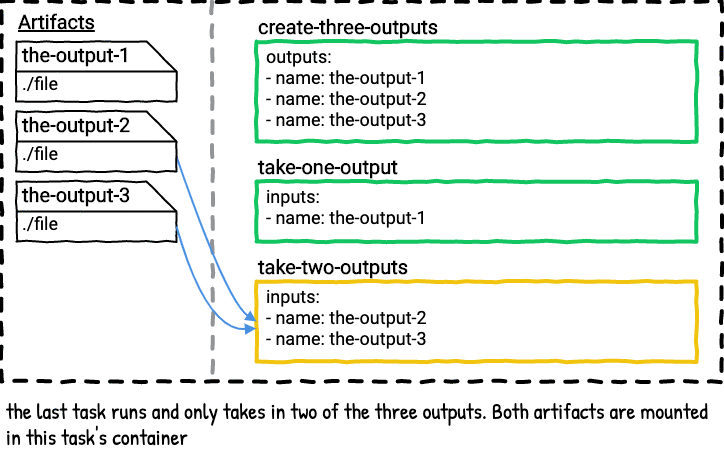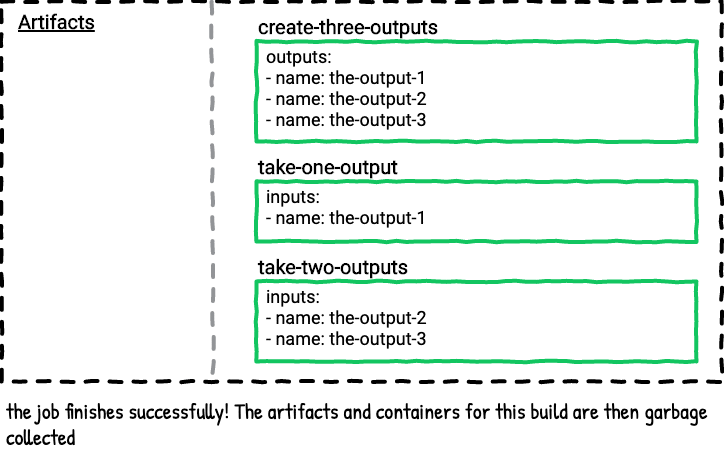
What happens if you have a task that has multiple outputs and a second task that only lists one of the outputs? Does the second task get the extra outputs from the first task?
The answer is no. A task will only get the artifacts that match the name of the inputs listed in the task’s config.
---
jobs:
- name: multiple-outputs
plan:
- task: create-three-outputs
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
outputs:
- name: the-output-1
- name: the-output-2
- name: the-output-3
run:
path: /bin/sh
args:
- -cx
- |
ls -lah
date > ./the-output-1/file
date > ./the-output-2/file
date > ./the-output-3/file
- task: take-one-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
# only one of the three outputs are
# listed as inputs
inputs:
- name: the-output-1
run:
path: /bin/sh
args:
- -cx
- |
ls -lah ./
cat ./the-output-1/file
- task: take-two-outputs
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
# this task pulls in the other
# two outputs, just for fun!
inputs:
- name: the-output-2
- name: the-output-3
run:
path: /bin/sh
args:
- -cx
- |
ls -lah ./
cat ./the-output-2/file
cat ./the-output-3/file
Here’s a visualization of the above job.
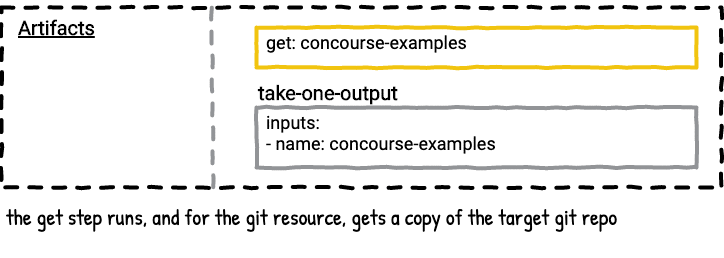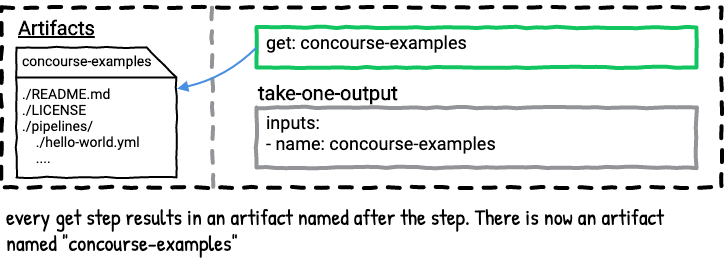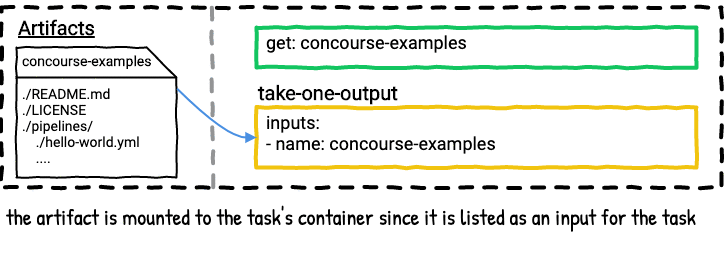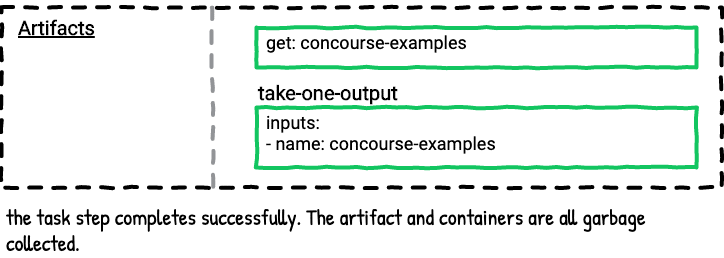
Example Six - Get Steps
The majority of Concourse pipelines have at least one resource, which means they have at least one get step. Using a get step in a job makes an artifact with the name of the get step available for later steps in the job plan to consume as inputs.
---
resources:
- name: concourse-examples
type: git
source: {uri: "https://github.com/concourse/examples"}
jobs:
- name: get-step
plan:
# there will be an artifact named
# "concourse-examples" available in the job plan
- get: concourse-examples
- task: take-one-output
config:
platform: linux
image_resource:
type: registry-image
source: {repository: busybox}
inputs:
- name: concourse-examples
run:
path: /bin/sh
args:
- -cx
- |
ls -lah ./
cat ./concourse-examples/README.md
Here’s a visualization for the above job.
I hope you found these example helpful with figuring out how inputs and outputs work within a single Concourse job.